Introduction
Once a problem has been decomposed into smaller tasks, it is useful to try and identify common themes or patterns that might exist in other programs.
This helps the programmer to save time reinventing the wheel when a solution to a given problem may already exist.
In this lesson, we will learn about:
- Pattern recognition
- Pattern generalisation and abstraction
- Representing parts of a problem or system in general terms

Pattern Recognition
Patterns exist everywhere. If you were to look at how your day is organised in your School, you will see that it follows a pattern:
- Your day will start at a set time
- It will be broken up into a number of lessons of a set length
- You will have a lesson with a teacher and the teacher will take a register
- You may or may not be set homework for a particular lesson.
This pattern holds true for each day of the week for most students in most schools and colleges.
This pattern can then be applied to any system that tracks and monitors student data, including attendance, punctuality and recording homework marks.
Such systems are known as Information Management Systems (IMS).
Pattern Recognition
Recognising patterns – things that are common between problems or programs – is one of the key aspects of computational thinking.
Pattern recognition is based on five key steps:
- Identifying common elements in problems or systems
- Identifying & interpreting common differences in problems or systems
- Identifying individual elements within problems
- Describing patterns that have been identified
- Making predictions based on identified patterns
Let’s investigate each of these steps in more detail.
Pattern Recognition
1. Identifying common elements in problems or systems
Once you identify a common pattern, there is more than likely going to be an existing solution to the problem.
For example, you might want to search for a student in a school IMS.
To do this you would need to use a searching algorithm, like a binary or linear search.
Pattern Recognition
2. Identifying & interpreting common differences in problems or systems
Two different Student IMS systems might have different ways of taking a register.
One system might simply record present and absent. Another system might record, present, planned absence, unplanned absence and late.
Although these are differences, all school and college IMS systems fundamentally need to be able to take a register. It’s just how they go about doing it is different.
Pattern Recognition
3. Identifying individual elements within problems
The elements can be broken down into inputs, processes and outputs.
In the case of the school register, the input will be a Character entered against the student name It could be ‘/’ or ‘P’ if the student is present, and ‘N’, ‘\’ or ‘L’ if they are not present.
Behind the scenes, a process will occur to add up the number of times the student was present for a lesson. This data will be saved in a database.
This data will also be output as a Percentage Attendance score for each student.
Pattern Recognition
4. Describing patterns that have been identified
Once you have identified a pattern, you can now start to describe it.
It might be a new pattern that occurs several times in your own program, or it might exist elsewhere in other programs.
In 1994, four Software engineers, nicknamed the ‘Gang of Four’, published a book on design patterns which formalised patterns in software use.
You can read more about “Gang of Four” design patterns here: https://www.tutorialspoint.com/design_pattern/design_pattern_overview.htm
Pattern Recognition
5. Making predictions based on identified patterns
Once you have identified a pattern you can speculate whether it can be reused in your existing program, or used in another program.
Pattern Generalisation & Abstraction
Abstraction means hiding the complexity of something away from the thing that is going to be using it.
For example, when you press the power button on your computer, do you know what is going on?
Of course not, your computer just turns itself on. That’s all you need to know.
The process of powering up your computer and loading the operating system into RAM memory from the boot sector has been hidden from you.
Abstraction in computational thinking is a technique where we split individual parts of the program down into imaginary ‘black boxes’ that carry out operations.
We don’t care HOW they do them only that they work.
Pattern Generalisation & Abstraction
There are two parts to this phase:
- Identify the information required to solve a problem. You will need to know the type and format of your information and when it is required.
- Filter out information you do not need and be able to justify this.
Pattern Generalisation & Abstraction
Let’s consider our Student IMS.
A teacher wants to look up details about a specific student. To do this, they type the student’s surname, click ‘enter’, and information is displayed.
The information needed for searching will be surname only.
This will give us a list of students with the specific surname, but the information brought back would include their first, middle and last name, and their year of registration.
The data needs to be text only.
Information not needed is gender, age and date of birth as all this will be obtained from the student search.
Pattern Generalisation & Abstraction
We can visualise our search procedure like this:
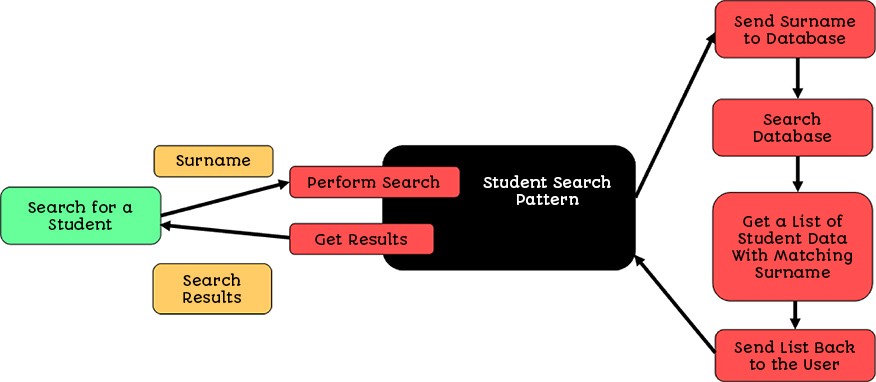
The ‘Search for A Student’ process does not know that the Student Search Pattern connects to a database and gets a list, all it knows is that it gives the black box a surname, and gets back some results.
This is Abstraction; the student search functionality is hidden away from the rest of the system.
Pattern Generalisation & Abstraction
Generalisation happens when you can spot common themes between patterns.
For example, you might want to search for students in a class, or who are being taught by a specific teacher.
Both of these involve some form of searching, the only thing that differs is what you are searching for.
Representing Parts of a Problem or System in General Terms
Consider the student search system, it can be represented using the following terms:
- Variables
- Constants
- Key Processes
- Repeated Processes
- Inputs
- Outputs
Let’s look at how the student search system can be represented like this.

Representing Parts of a Problem or System in General Terms
Variables
These are the values that will change – in this case the surname of a student.
Constants
This will be something that is likely to remain fixed for a while, e.g. a student will typically study a 2-year course.
Key Processes
These are the things that are critical to the system – for example, searching the database for a given student surname.
Representing Parts of a Problem or System in General Terms
Repeated Processes
These are things that happen multiple times, for example adding students with matching surnames to the list of students.
Inputs
The values entered into the system, in this case, it is the student surname.
Outputs
The information produced by the system, in this case, a list of students with a matching surname, also including their first name, middle name and year of registration.
Lesson Summary
Patterns are things that are the same within a problem and between problems.
Identifying patterns means that there is probably an existing solution already out there.
Pattern recognition is based on 5 key steps.
Abstraction is hiding the complexities of one pattern from another.
Generalisation is spotting things that are common between patterns.
We can represent parts of a system in general terms, including Variables, Constants, Key Processes, repeated Processes, Inputs and Outputs.
